 Chris Koehncke
Chris KoehnckeDoes your mobile phone provide better quality than a typical webcam? I'll test some virtual webcam software for mobile.
1:0 Real Time Communications
Kranky Geek Returns to Google SF Fri October 27
 Chris Koehncke
Chris Koehncke
This Friday, October 27, 2017, the Kranky Geek team will be hosting for the 4th consecutive year our #webrtc event at Google San Francisco. It’s not too late to register at www.krankygeek.com!
In the early days, the fact that WebRTC worked was amazing, even more so due to the simplicity. Imagine a complete audio/video communications solution using only 3 API calls. Nearly any developer could build something. It was that easy. But WebRTC was yet another technology asteroid hurtling through deep space.
WebRTC’s premise was for multi-person real-time communications. But what happens when one of those “persons” is not a human, but rather a machine. A machine, listening, looking and responding. It’s not just about to happen, it’s already happening.
For this year’s Kranky Geek, we’ve tilted our agenda to the topic of 1-to-0 (1:0) communications where only 1 party is a human, the other a machine. Vision recognition, natural language processing, and machine learning — these easily intersect with the core capabilities of WebRTC. At Kranky Geek, we’ll provide you early knowledge on how to intersect these technologies.

Recently returning from China, Badri Rajasekar and I got a first-hand demonstration of China’s SkyNet which offers near-instant facial and vehicle recognition via a network of 20,000 cameras. Like it or not, you have to be impressed with the technology. Similarly, our hotel had a live video recognition (for Chinese Nationals) to register their hotel stay.
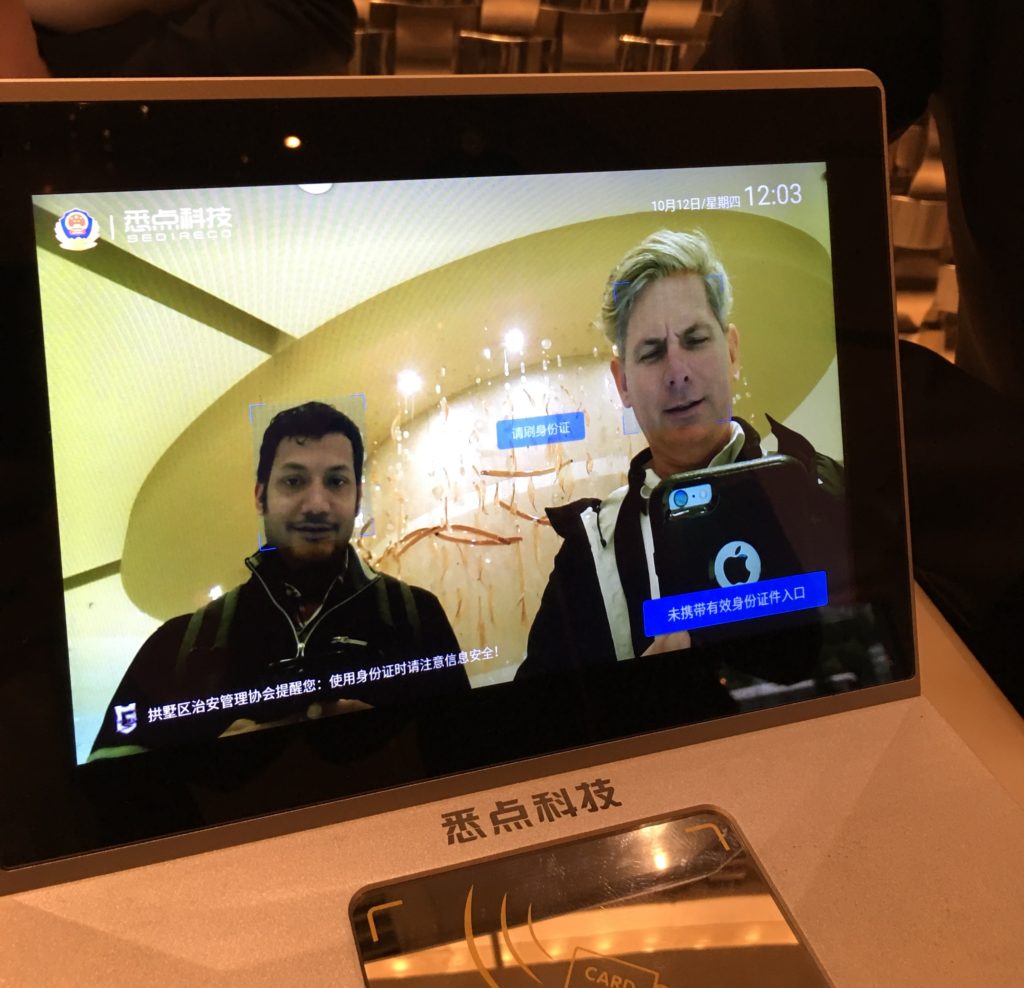
The power of WebRTC’s simplicity and ability to easily re-direct and manipulate the real-time audio/video sets the stage for a whole new era of communications applications.
